Designing a Production-Grade RAG Architecture
In this article
Large Language Models (LLMs) respond with radical overconfidence and hallucinate facts with alarming fluency. Retrieval-Augmented Generation (RAG) exists to eliminate this guessing by grounding LLM outputs in retrieved, verifiable data from your private knowledge bases.
In this guide, we’ll design a complete, production-grade RAG architecture using open-source technologies. We'll walk through the key design decisions—from ingestion pipelines to reranking strategies—that transform a basic prototype into a resilient enterprise system.
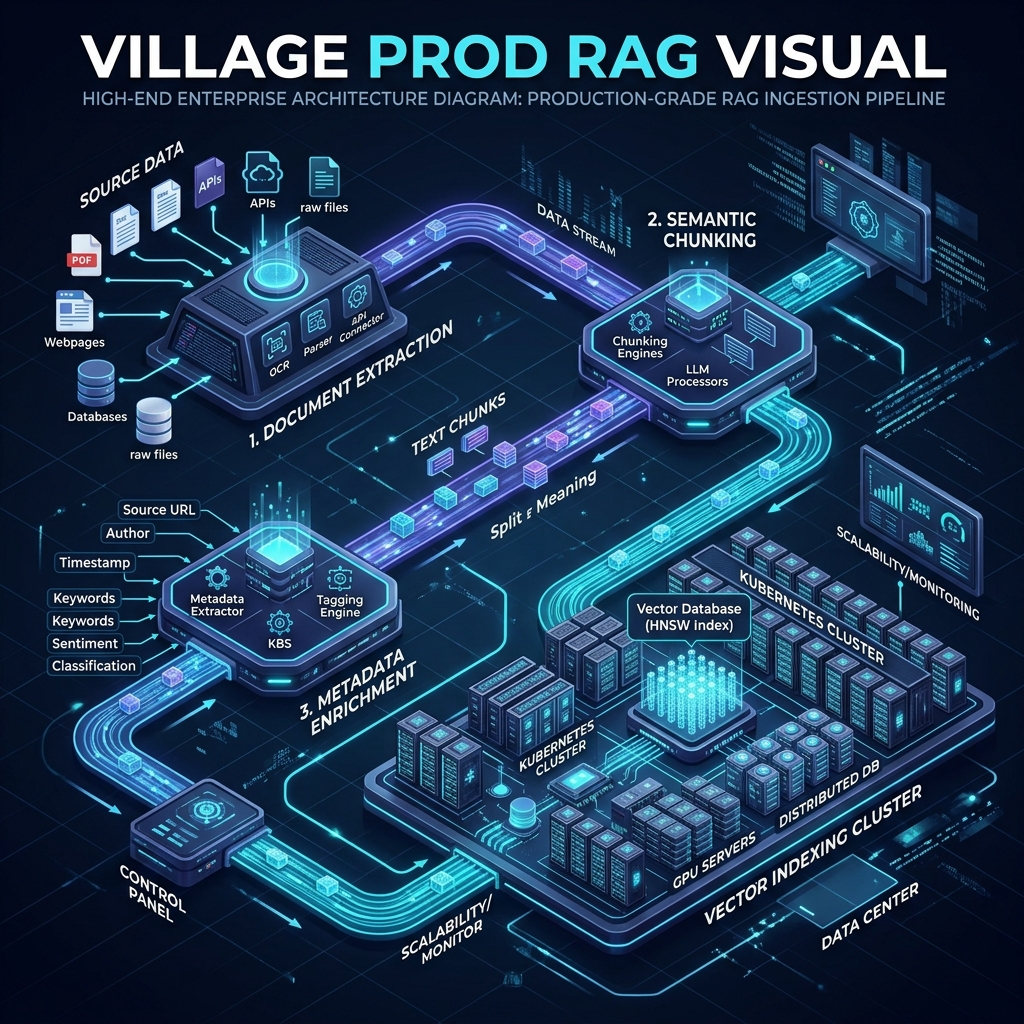
The Two Processes of RAG
A production RAG system is composed of two distinct pipelines:
1. Ingestion Pipeline
This process extracts text from your knowledge bases and stores it in a searchable format. It is the most critical and complex part of the system. If your ingestion is poor, your retrieval will fail, rendering the system useless.
2. Retrieval + Generation
Once data is searchable, you need a way to find relevant extracts based on a user's prompt (Retrieval) and inject them as context for your LLM (Generation).
Core Design Decisions
There is no "perfect design" that works for all data. Your architecture must follow your data:
- Formats: PDF, HTML, JSON, or Free Form?
- Structure: Sections, hierarchies, tables, or legal references?
- Metadata: What additional context needs to be indexed?
- Modality: Is there non-text data (images, video)?
Search Strategies: Sparse vs. Dense vs. Hybrid
Keyword Search (Sparse Vectors)
The traditional search engine approach. Words in a query are matched against words in documents. Modern implementations use BM25, which assigns weights to tokens using Inverse Document Frequency (IDF) to reduce noise from common words.
Embedding Similarity (Dense Vectors)
Embeddings create a numeric vector representation of text that captures semantic meaning. Similar words are closer in vector space. Cosine Similarity is used to find texts with similar meanings, even if the exact keywords don't match.
Decision: Hybrid Search
In production, a Hybrid Search combining both strategies often performs best. A common ratio is weighting search results 70% to embeddings (for semantic reach) and 30% to keywords (for specific technical codes or names).
Database Selection: Qdrant
For this architecture, we recommend Qdrant. It supports both Dense and Sparse vectors natively and performs hybrid queries out-of-the-box. It uses Reciprocal Rank Fusion (RRF) to combine results—the industry standard for RAG.
Other viable options include: Weaviate, Pinecone, and Milvus.
The Ingestion Pipeline in Detail
An effective pipeline follows these steps:
[!TIP] Chunking Strategy Embeddings work best with small, semantically cohesive chunks.
- Length: 200–400 tokens is the sweet spot. Complex legal documents may require up to 600.
- Breaks: Avoid strict character counts. Prefer paragraph breaks or sentence endings to keep context intact.
- Overlap: An overlap of 10–20% between chunks improves recall by ensuring boundaries don't split vital information.
Advanced Retrieval Techniques
Adjacent Chunks (Windowing)
If a search returns a specific chunk, the chunks immediately before and after it are likely relevant. Enriching your search results with adjacent chunks (1–2 indexes away) significantly boosts the context provided to the LLM.
Reranking
Hybrid search often retrieves "noisy" results. Reranking uses specialized models (Cross-Encoders) to sort the initial results by true relevance to the user's query.
- Workflow: Retrieve Top 10 → Add adjacent chunks (total ~18) → Rerank → Send Top 5 to LLM.
- Models:
BAAI/bge-reranker-baseis a strong open-source choice that can run on CPUs.
Generation and Orchestration
Context Injection
Inject chunks into the LLM conversation as Tool messages (if supported) or structured blocks in the System message.
- System Message: Defines rules, behavior, and guardrails.
- Tool/Context Message: The retrieved chunks + metadata (citations).
- User Message: The actual question.
Orchestration Frameworks
Using an orchestrator like LangChain or Semantic Kernel simplifies tool calling and allows the LLM to interpret and refine the user's query before searching the vector store.
Production Deployment Checklist
| Component | Recommendation | Why? |
|---|---|---|
| Vector DB | Qdrant (Docker) | Native hybrid search & RRF support. |
| Embeddings | bge-small-en-v1.5 |
Fast, high-quality, runs on CPU. |
| Reranker | bge-reranker-base |
Dramatically improves precision. |
| LLM | GPT-4o or Llama 3 70B | Reliable reasoning and tool calling. |
| Orchestrator | LangChain / Semantic Kernel | Simplifies multi-step RAG workflows. |
Summary: Building for Precision
Building your own RAG architecture allows you to tailor chunking, weighting, and reranking to your specific data. While off-the-shelf solutions exist, the most accurate systems are those designed with a deep understanding of the underlying knowledge base.
[!WARNING] Key Pitfalls to Avoid:
- Using too large a chunk size (dilutes semantic meaning).
- Neglecting keyword search (misses specific technical terms).
- Skipping the reranking step (increases LLM hallucination risk).
The Production AI Engineer
Go beyond simple prototypes. Master enterprise-grade RAG, multi-tenant databases, autonomous multi-agent networks, strict guardrails, and GPU cost optimization in our complete 122-page systems guide.
Related Guides
Build a Local LLM Zero-Shot Classifier You Can Actually Deploy
Learn how to run zero-shot text classification on a local model with Ollama, enforce strict JSON outputs, and add confidence-aware routing for production triage.
The Complete Developer Guide to Running LLMs Locally: From Ollama to Production
Everything you need to run LLMs on your own hardware in 2026: VRAM sizing, model formats, an 8-tool comparison table, a full local RAG pipeline, and Docker production deployment with GPU passthrough and Nginx auth.
Event-Driven Architecture for Agentic AI: The Architect's Guide
A comprehensive architectural guide to designing resilient, real-time agentic AI systems using event-driven architecture — covering loose coupling, fault isolation, reference architecture, and governance patterns.